Table of Contents
Passive Reader-Writer Lock : Scalable Read-mostly Synchronization Using Passive Reader-Writer Locks
Passive reader-writer lock (Prwlock) is a reader writer lock designed for scalable read-mostly synchronization. It provides scalable read-side performance as well as small writer latency for TSO architectures. It is mainly implemented in kernel mode. We use it to protect address space tree based on Linux 3.8.
Faculty
Students
- Heng Zhang Ran Liu
Background
Reader-writer locking is an important synchronization primitive that allows multiple threads with read accesses to a shared object when there is no writer, and blocks all readers when there is an inflight writer. While ideally rwlock should provide scalable performance when there are infrequent writers, it is widely recognized that traditional centralized rwlocks have poor scalability.
While there have been a number of efforts to improve the scalability of rwlocks, prior approaches either require memory barriers and atomic instructions in readers, or significantly extend writer latency, or both. Further, many prior designs cannot cope with OS semantics like sleeping inside critical section, preemption and supporting condition synchronization (e.g., wait/signal). Hence, researchers sometimes relax semantic guarantees by allowing readers to see stale data (i.e., RCU). While RCU has been widely used in Linux kernel for some relatively simple data structures, it, however, would require non-trivial effort for some complex kernel data structures and may be incompatible with some existing kernel designs. Hence, there are still thousands of usages or rwlocks inside Linux kernel.
Related Work
Following table shows the features of popular reader-writer synchronizations.

Big-reader Lock (brlock)
The key design of brlock is trading write throughput for read throughput. There are two implementations of brlock:
- requiring each thread to obtain a private mutex to acquire the lock in read mode and to obtain all private mutexes to acquire the lock in write mode (brlock1).
- using an array of reader flags shared by readers and writer (brlock2).
C-SNZI
C-SNZI uses scalable nonzero indicator (SNZI) to implement rwlocks. The key idea is instead of knowing exactly how many readers are in progress, the writer only needs to know whether there are any inflight readers. This, however, still requires actively maintaining reader status in a tree and thus may have scalability issues under a relatively large number of cores due to the shared tree among readers.
Cohort Lock
Irina et al. leverage the lock cohorting technique to implement several NUMA-friendly rwlocks, in which writers tend to pass the lock to another writer within a NUMA node. While writers benefit from better NUMA locality, its readers are implemented using per-node shared counters and thus still suffer from cache contention and atomic instructions
Percpu-rwlock
Linux community is redesigning a new rwlock, called percpu rwlock. Although, like prwlock, it avoids unnecessary atomic instructions and memory barriers, its writer requires RCU-based quiescence detection and can only be granted after at least one grace period, where all cores have done a mode/context switch.
Read-Mostly Lock
From version 7.0, the FreeBSD kernel includes a new rwlock named reader-mostly lock (rmlock). Its readers enqueue special tracker structures into per-cpu queues. A writer lock is acquired by instructing all cores to move local tracker structures to a centralized queue via IPI, then waiting for all the corresponding readers to exit. Like prwlock, it eliminates memory barriers in reader fast paths. Yet, its reader fast path is much longer compared to prwlock, resulting in inferior reader throughput. Moreover, as IPIs need always to be broadcasted to all cores, and ongoing readers may contented on the shard queue, its writer lock acquisition is heavyweight.
Read-Copy Update
RCU increases concurrency by relaxing the semantics of locking. Writers are still serialized using a mutex lock, but readers can proceed without any lock. As a result, readers may see stale data. RCU delays freeing memory until there is no reader referencing to the object, by using scheduler-based or epoch-based quiescence detection that leverage context or mode switches. In contrast, the quiescence detection (or consensus) mechanism in prwlock does not rely on context or mode switches and is thus faster due to its proactive nature. Its relaxed semantics essentially break the all-ornothing atomicity in reading and writing a shared object, which also places several constraints on the data structures, including single-pointer update and readers can only observe a pointer once (i.e., non-repeatable read).
Our approach
The key of prwlock is a version-based consensus protocol between multiple non-communicating readers and a pending writer. Prwlock leverages bounded staleness of memory consistency to avoid atomic instructions and memory barriers in readers’ common paths, and uses message-passing (e.g., IPI) for straggling readers so that writer lock acquisition latency can be bounded.
Prwlock introduces a 64-bit version variable to the lock structure. Each writer increases the version and waits until all readers see this version. Prwlock introduces a message-based consensus protocol to let the writer actively send consensus requests to readers when a supposed reader never enters the read-side critical section again.
To address the sleeping reader issue, prwlock uses a hybrid design by combining the above mechanism with traditional counterbased rwlocks. Prwlock tracks two types of readers: passive and active ones. A reader starts as a passive one and does not synchronize with others, and thus requires no memory barriers. A passive reader will be converted into an active one before sleeping. A shared counter is increased during this conversion. The counter is later decreased after an active reader released its lock. Like traditional rwlocks, the writer uses this counter to decide if there is any active reader. (As sleeping in reader-side critical section is rare, prwlock enjoys good performance in the common case, yet still preserves correctness in a rare case where there are sleeping readers.)
Decentralized parallel wakeup
Our further investigation uncovers that the main performance scalability issue comes from the cascading wakeup phenomenon. When a writer leaves its write-side critical section, it needs to wake up all readers waiting for it. As there are multiple readers sleeping for the writer, the writer wakes up all readers sequentially. Hence, the waiting time grows linearly with the number of readers.
To speed up this process, prwlock distributes the duty of waking up tasks among cores. In general, this would risk priority inversion, but all prwlock readers always have equal priority.
In our designed, each core maintains a percore wakeup queue (PWake-queue) to hold tasks sleeping on such a queue, each of which sleeps on a wakeup condition word.
And the following figure shows the state transition graph

- When a running task is going to sleep on a condition, it is removed from Run-queue and inserted into PWake-queue.
- The processes check whether the tasks in PWake-queue meet their conditions. If so, they are moved to the Run-queue from the PWake-queue.
- A task in Run-queue is selected to execute by scheduler.
- If no runnable tasks on the core, the idle cores use monitor & mwait instructions to sleep on a global word.
- When a writer finishes its work, it wakens up the idle cores by touch the word.
Since as all operations are done locally in each core, no atomic instructions and memory barriers are required.
Result
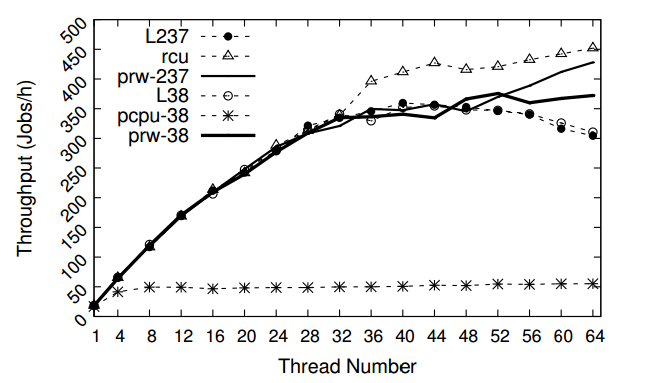
We compare the performance of prwlock with several alternatives, including the default rwlock in Linux for virtual memory, percpu read-write lock, and an RCUbased VM design (RCUVM). We are not able to directly compare prwlock with brlock as it has no sleeping support. As RCUVM is implemented in Linux 2.6.37, we also ported prwlock to Linux 2.6.37. As different kernel versions have disparate mmap and page fault latency, we use the Linux 2.6.37 kernel as the baseline for comparison. For the three benchmarks, we present the performance scalability for Linux-3.8 (L38), percpurwlock (pcpu-38) and prwlock on Linux 3.8 (prw-38), as well Linux 2.6.37 (L237), RCUVM (rcu) and prwlock on Linux 2.6.37 (prw-237) accordingly.
We use three workloads that place intensive uses of virtual memory: Histogram, which is a MapReduce application that counts colors from a 16GB bitmap file; Metis from MOSBENCH, which computes a reverse index for a word from a 2GB Text file residing in memory; and Psearchy, a parallel version of searchy that does text indexing. They represent different intensive usages of the VM system, whose ratio between write (memory mapping) and read (page fault) are small, medium and large.
Histogram
 Because currently RCUVM only applies RCU to page fault on anonymous pages, while histogram mainly faults on a memory-mapped files, the RCU kernel in this workload does not perform well.
Because currently RCUVM only applies RCU to page fault on anonymous pages, while histogram mainly faults on a memory-mapped files, the RCU kernel in this workload does not perform well.
Metis

Psearchy
Publication
Liu, Ran, Heng Zhang, and Haibo Chen. “Scalable read-mostly synchronization using passive reader-writer locks.” Proceedings of the 2014 USENIX conference on USENIX Annual Technical Conference. USENIX Association, 2014.[pdf]
Related Download
Now, we only open source the kernel we modified based on Linux 3.8. We plan to open source more later
Please download the patch here [prwlock_kernel3.8_patch.zip]