今年的第17届ChinaSys研讨会在广东珠海召开。ChinaSys是中国计算机系统及相关领域的学术团体,宗旨是为本领域的研究者和从业者提供资源共享、交换思想和会晤的平台,促进中国计算机系统行业的发展。本次参会197人,共有16篇来自不同顶会的文章在本次ChinaSys上进行介绍。本次IPADS共派出10名博士参加了本次研讨会。
Nian Liu, Binyu Zang, and Haibo Chen Shanghai Jiao Tong University
这个session的第一篇是来自我们IPADS实验室的工作。随着使用ARM架构的低功耗、高性能服务器的兴起,包括亚马逊、华为在内的多家互联网企业已经开始部署ARM服务器。向ARM服务器上迁移现有应用迫在眉睫。ARM与x86架构的主要区别之一在于其使用了不同的内存模型。在ARM处理器中,针对不同地址、没有依赖关系的访存指令被允许乱序执行。现有应用需要添加非常耗时的硬件内存屏障从而保证其正确执行。不同于ARM移动处理器,硬件内存屏障在服务器场景下对性能有着显著的影响,在移植现有应用到ARM服务器时应被严肃考虑。
这个工作针对ARMv8服务器中多种不同访存保序方案的性能影响进行了全面、详尽的分析与测试。我们将应用中需要保序的场景抽象成一系列精简模型以排除其他因素对性能的影响,从而分析、总结出不同保序方案的性能特性,最后在频繁使用内存屏障的应用中验证了我们的结论。基于这些分析,我们为开发者移植现有应用到ARMv8服务器提供了在不同场景使用保序方案的指导意见。
除此之外,我们发现硬件内存屏障的巨大性能开销主要来自于一种特定的使用模式。针对这种模式,本工作提出了一种有效的机制,Pilot,其利用硬件访存的原子性(single-copy atomicity)实现相同功能的同时,消除了使用硬件内存屏障导致的巨大开销。
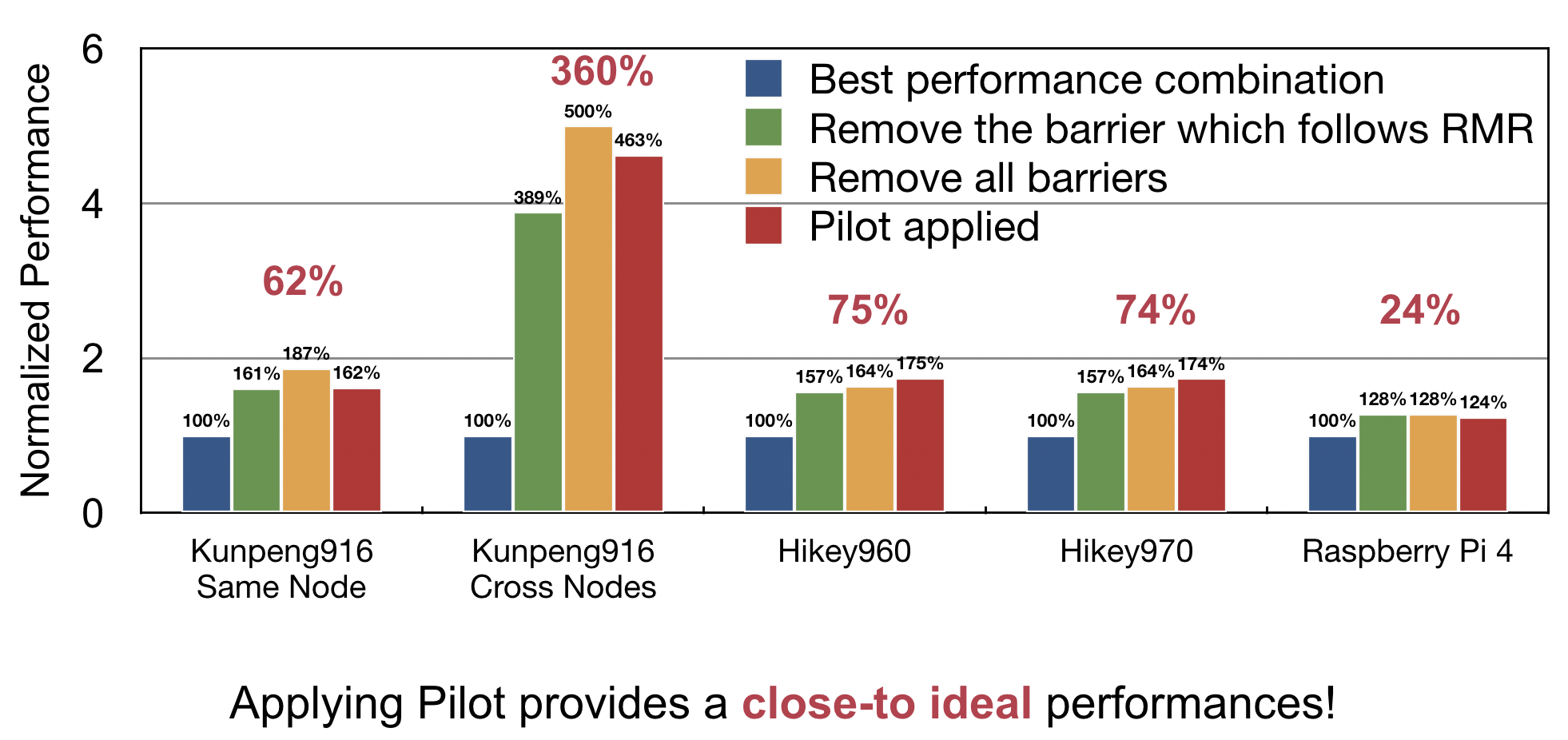
在不同的测试集中,使用Pilot能够带来10%到380%的性能提升,最终达到近似没有使用硬件内存屏障的理想性能。
Liang Zhu, Chao Chen, Zihao Su, Weiguang Chen, Tao Li and Zhibin Yu Shenzhen Institutes of Advanced Technology, Chinese Acadenmy of Sciencesm, University of Florida
当前,区块链技术不断发展,应用不断普及。同时,区块链的性能较慢问题仍未得到很好地解决。本篇工作提出一种针对区块链系统的微体系结构基准测试方法BBS。通过使用机器学习方法与模糊集合理论,BBS可以选择出重要的需要关注的微体系结构指标,并且能够发现冗余的基准测试程序以节省测试时间。
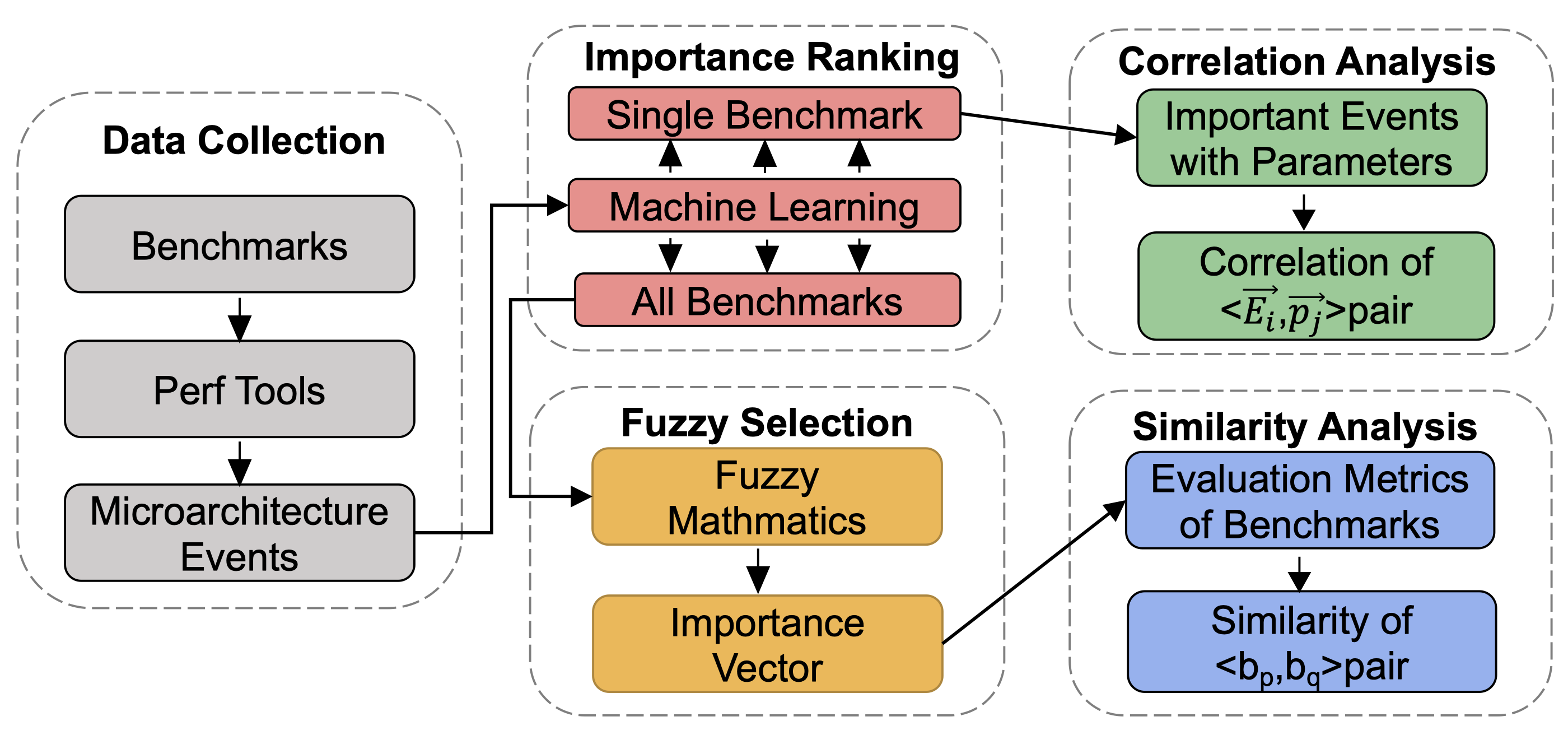
BBS工作流程示意图
BBS的工作流程分为以下五个部分:1)数据收集;2)重要性评级;3)模糊选择;4)相关性分析;以及5)相似度分析。在数据收集过程中,BBS通过运行现有的基准测试程序,并通过Linux Perf Tool统计每个基准程序的单位周期指令数(IPC),收集微体系结构事件信息,如分支预测正确率等。在这个过程中,总共有234个事件被收集。在重要性评级中,通过SGBRT(一种机器学习算法)来学习这些微体系结构事件对IPC的影响,从而完成对各事件的重要性评级。经过重要性评级,虽然对事件排序了,但是事件总数没有减少。同时,我们不能说第十个重要第十一个就不重要了,所以需要一个方法有依据的选取,因此在模糊选择过程中使用模糊集合的方法来选择。在相似性分析中,BBS构建Similarity radar map与similarity matrix,通过比较两个基准程序的这两种数据,BBS能够去除冗余的测试,从而节省总的测试内容。
本工作在Hyperledger caliper与blockbench基准测试程序集合上验证了BBS的有效性。本工作同时发现许多微体系结构事件在不同基准测试程序中重要性不一样,即不同的工作负载对不同的微体系结构部件的需求有较大差异;同时发现分支预测相关事件对大部分基准测试程序有较大影响。
Zhenyu Ning and Fengwei Zhang Southern University of Science and Technology
上午的第三个talk来自南科大的张锋巍教授。
本篇工作称为Nailgun(钢枪),意指在ARM处理上的Non-Secure和Secure两个特权间的隔离“墙”上打洞,可以将攻击者指定的payload注入EL3。
ARM v7处理器提供了核间调试能力(inter-processor debugging model),可以允许用户在不使用外接JTAG等辅助条件下对ARM上的单个核心进行调试。这种调试能力通常在终端消费设备上是应该被禁止使用的。本文调研了市面上的各类ARM设备,发现在云服务器、手机端、IoT上不少存在debug authentication没有被安全配置的问题,导致EL1可以对其他任意核发送调试信号,并在调试状态下进行提权,进而达到对更高特权的EL3内的安全内存的任意读写能力。利用该缺陷,本文作者从手机中能成功提取指纹TA存有的敏感信息。
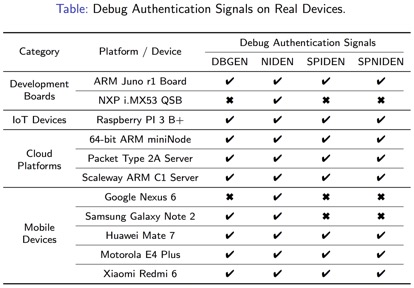
图:作者测试的设备及其debug authentication缺陷情况列表
作者将这一问题提交给各大厂商并得到确认——CVE-2018-18068。这个工作提醒我们,体系结构中新特性的增加、复杂度的提升有可能会导致意想不到的安全问题。
Xia Zhao, Almutaz Adileh, Zhibin Yu, Zhiying Wang, Aamer Jaleel, and Lieven Eeckhout Ghent University, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, National University of Defense Technology and Nvidia
这片论文是根特大学和中科院深圳先进技术研究院的合作项目,主要研究了对GPU中LLC cache动态配置带来的性能优化。新兴的GPU应用程序需要越来越高的计算能力,导致GPU需要越来越多的流处理器(SM)。当前的GPU架构中最后一集缓存(LLC)是所有SM共享的,虽然共享的LLC有较低的miss率,但是却带来了带宽的瓶颈。我们发现对于那些跨SM共享数据的workload来说,私有的LLC通过多份的拷贝来增加带宽,显著地提升性能。本文通过一种自适应GPU last level memory的调节,提升了共享只读数据程序的带宽,同时还能降低了GPU的能耗。
在传统的cpu中 shared cache和private cache会带来容量和延迟之间的trade off,shared cache能够有较多的容量,但是访问的延迟较长;private cache有较快的响应时间,但是容量较少。然而在GPU中,shared cache和private cache之间的trade off发生一些变化。Shared cache拥有较大的容量,但是却存在带宽的瓶颈,特别是当多个SM同时访问相同的shared data。对于private cache来说,虽然容量较小,但是多个SM可以并发访问private cache中的数据,有较高的带宽。
在GPU中共享的LLC是可以被所有的SM访问,私有的LLC只能被特定的SM cluster访问,如图。
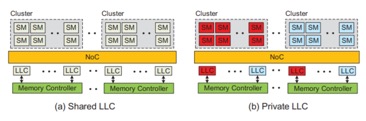
作者将GPU程序分成三类,1、Shared cache friendly applications这类程序往往访问自己cluster中的LLC cache;2、Private cache friendly applications这类程序会访问大量其他cluster中的LLC cache;3、Shared/private cache neutral applications这类程序并不在意LLC中cache的划分。

通过以上的观察,可以发现动态配置share/private LLC是非常有必要的。作者提出了一种重新配置的LLC的规则:
1、shared -> private: 如果两种LLC的管理机制的miss rate相同,那么将shared cache转换为private cache
2、shared -> private: 如果将shared cache转换成private cache增加的带宽大于cache miss的overhead,那么将shared cache转换成private cache。其中对带宽的计算为:BW = LLChit·LSP·LLCBW + LLCmiss·MEMBW。通过比较两者的带宽来决定是否要状态的转移。
3、Private -> shared: 当执行完1M的cycle或者一个新的kernel启动的时候,将private cache转换为shared cache
实现LLC的动态配置并不复杂,只需要动态的改变LLC的索引。文中使用Hierarchical Crossbar来实现片上通信。H-Xbar是一个多状态蝶式网络。对于GPU来说noc不需要实现节点的全相联,可以通过2-stage 路由代替:MC-router和SM-router
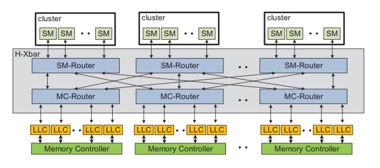
在默认的情况下H-Xbar提供share LLC,如果绕过MC-router就可以实现private LLC。同时因为采用H-Xbar连接方式替代全相联,只需要将特定的LLC和SM cluster相连,减少了noc上的电路,降低了noc的能耗。
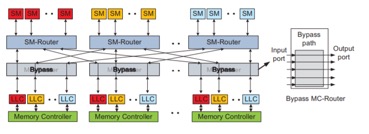
该论文提出了一种新的GPU LLC的管理机制。通过动态配置LLC,实现了平均28.1%的性能的提升和26.6%的noc能耗降低。该工作是第一个将private cache引入GPU微架构中,结合private和shared cache之间的动态调度,提升了GPU的带宽。同时该工作也存在一些可以改进的方向,对于shared和private cache转换的粒度过粗,如果能够实现更加细粒度的cache属性地转换,可能带来更多的性能提升。
Sijie Shen, Rong Chen, and Haibo Chen Shanghai Jiao Tong University
第一天session1的最后一个报告是来自上海交通大学IPADS实验室的目前在投工作。HTAP是传统数据库中OLTP和OLAP两种工作负载的结合,旨在能够快速地在新产生数据上做实时分析。该工作分析了目前业界和学术界对于HTAP系统提出的一些需求:高效性、新鲜性、资源节约性,并且分析了目前常见HTAP架构的优缺点,均不能很好地达到这三个要求。
该报告通过对OLTP数据库在支持高可用性(HA)架构和HTAP架构进行观察发现,HA和HTAP两者在架构上极为相似,OLTP系统可以通过复用HA上的设计来实现HTAP的功能。
通过分析复用HA架构实现HTAP所面临的挑战,该报告采用基于epoch的设计进行处理。在实现的系统原型上,该系统可以和先进的OLTP数据库和OLAP数据库相比较,并且相比于现有HTAP数据库更符合三大需求。
Youren Shen, Hongliang Tian, Yu Chen, Yubin Xia, Shoumeng Yan, and Kang Chen
Tsinghua University, Ant Financial, Shanghai Jiao Tong University
下午的第一个talk是来自清华大学团队的关于可信硬件Intel SGX的LibOS工作。
已有的SGX LibOS如Graphene-SGX只支持一个LibOS面向一个App,这种设计类似Unikernel,但由于SGX体系结构自身的特点,导致EPC消耗过多,fork时启动一个新的实例时间太久,以及IPC时实例间数据加解密等性能开销。另一类设计如Oblivate采用类Microkernel的做法,将服务作为一个单独的SGX实例存在,支持了1:N的服务模型,减小了EPC的使用,但IPC的高延迟缺点依然存在。

图:LibOS架构比较
本文作者为了克服这个缺点,在SGX LibOS中引入了SFI (Software Fault Isolation)机制,将不同的task隔离在不同的domain当中,而共享同一个地址空间和同一个LibOS。不同于基于内存安全或类型安全语言的SFI隔离机制(如Microsoft Research的Singularity),本文使用Intel MPX特性,对每个task的code和data的内存上下界进行限制,防止不同task间相互干扰。为预防SFI的检查代码被绕过,该工作还结合了CFI (Control-Flow Integrity)。因为源码插桩部分来自Occlum工具链,为减小对编译器的信任,该工作专门实现了verifier来检查ELF程序隔离的正确性。为保证LibOS自身的安全特性,Occlum用Rust语言实现。
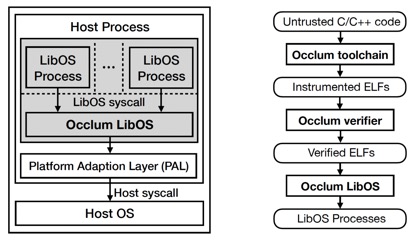
图:Occlum整体架构和流程
从性能表现上看,在进程创建方面,Occlum的SFI-based posix_spawn比Graphene的vfork快了13倍到6600倍不等,IPC则快了3倍。本工作在MPX的SFI方面做了不少优化,开销相对较低,内存load 25%而内存store 4%左右。
Xingbin Wang, and Rui Hou State Key Laboratory of Information Security, Institute of Information Engineering, Chinese Academy of Sciences
这篇论文是中科院信息安全重点实验室的一个工作。当前深度神经网络非常的火,但是也存在一些安全的隐患,比如对抗样本攻击,通过增加一个微小的扰动,可以将原本正确的识别结果出错。特别是在无人车等相关领域,一旦遭到了对抗样本攻击,其后果非常的严重。已有的对抗样本防御的方法主要分为两类,一类是神经网络方法,另一类是非神经网络方法。该工作将对抗样本的防御应用在DNN的加速器中,有效的提高了对抗算法的性能。
DNNGuard主要设计想法:
1、紧耦合的异构体系架构,DNN加速器和host实现在不同的体系架构,能够定制专门的计算模块
2、高效的任务层次的数据通信与共享,能够复用本地数据,支持任务的并发,保证了read-after-write依赖
3、高效的任务层次的同步与调度。DNNGuard实现了片上调度器以及监管者
4、扩展了AI指令集,扩展的指令集主要用于数据的交互以及同步,核内的通信以及调度,传统的设计中检测网络和目标网络可能需要通过PCI-E进行连接,在DNNGuard中使用的片上缓存进行通信
DNNGuard扩展了硬件实现:1、扩大了片上PE范围,能够使用更多的片上缓存;2、实现了片上调度模块,用于调度不同的任务;3、扩展了AI 指令集,其中包括了配置层,数据层和控制层。
用于对抗防御的检测网络相较于目标网络有较大的不同,检测网络通常比较小,往往只有5-15层,同时会与目标网络共享中间的映射,采用新的激活函数。同时检测网络可以拆分为cpu部分和加速器部分,这两部分的通信可以通过片上缓存进行,相交于传统的DRAM通信,能够有较高的性能提升。
DNNGuard通过增加了47%片上面积提升了对抗算法的性能,同时提出了一个弹性的DNN加速器架构方案以及弹性的管理机制与扩展的AI指令集。
Jingwen Leng, Alper Buyuktosunoglu, Ramon Bertran, Pradip Bose, Quan Chen, Minyi Guo, and Vijay Janapa Reddi Shanghai Jiao Tong University, IBM and Harvard University
这篇论文介绍了关于硬件加速器容错的工作。随着硬件不断发展,种类繁多的硬件加速器开始被用于替代CPU执行特定任务。但是随着硬件加速器的部署的越来越多,一个系统单位时间内发生内硬件加速器错误的可能性也越来越高,如何支持硬件加速器的容错是一个非常关键的问题。这篇论文通过利用高可靠的CPU保障硬件加速器的可靠性。
硬件加速器的容错方式应该满足性能和通用性两项指标。硬件加速器是为了提升特定任务的性能而引入的,所以容错机制不能导致硬件加速器性能变得比CPU执行特定任务还低。另一方面,现在硬件加速器没有统一抽象,且针对不同任务有不同的硬件加速器,容错技术必须有足够的通用性,不必为每一种硬件加速器单独设计。现有的对于硬件加速器的容错机制主要有两种方式,但它们无法同时保证以上两种指标。第一种容错方式是使用CPU定时地对硬件加速器状态设置备份,即检查点(checkpoint)机制。这种方式通用性高,但是需要定时地为硬件加速器状态备份,对性能有非常大的影响。第二种容错方式通过利用代码段的幂等性,去除上一种备份方式对性能的影响。一个代码段是幂等的,是指这个代码段执行任意多次,它对程序的影响是是固定不变的。借由代码段的幂等性,如果硬件加速器发生错误,只需要简单地重新执行该代码段即可。这种方式不影响程序正常执行的性能,但为了判断代码段的幂等性需要引入指令集代码分析,通用性较差。
针对现有研究领域的空白,本文提出了非对称容错(Asymmetric Resilience)系统架构,一句话概括,就是用高可靠的CPU架构对低可靠的加速器架构容错。该架构主要有两方面,一方面是利用任务粒度的幂等性,任务的幂等性是根据任务多次执行时的读操作(输入)的内存区域和写操作(输出)的内存区域是否一致决定的,如果一致则该任务具有幂等性。利用任务的幂等性同样无需备份,保证了性能。另一方面,为了保证硬件错误写坏的内存不会被其他硬件观察到,该结构为CPU和硬件加速器提供容错域保证错误隔离性,这种方法适用于所有硬件,有很高的的通用性。
在实现上,本篇文章1)通过维护内存以页为粒度的读写权限保证了内存地址空间的隔离;2)通过对任务代码进行符号执行的静态分析,分析任务的输入、输出内存空间以及任务的幂等性;3)对于不满足幂等性的任务,任然需要使用备份方式容错。但是本文提出了一个观察并基于此作出了优化,假设有两个任务kernel1和kernel2,虽然kernel2不满足幂等性,但是它的输入完全依赖于kernel1的输出,那么对于kernel2的容错恢复只需要按序将kernel1和kernel2一起执行即可,无需为kernel2的执行备份。
最终,通过实验评测分析,非对称容错系统架构在无错误发生时,对任务正常执行带来的性能影响不超过1%。作为权衡,虽然基于非对称容错系统架构的任务需要在容错恢复时执行更多时间恢复,但由于硬件出错仍然是小概率事件,这一部分开销是可以接受的。
这篇工作是由华中科技大学和加州大学圣巴巴拉分校合作完成的,发表于2019年的MICRO中,其中一作左鹏飞被选入了华为“天才少年”计划。
这篇工作主要针对在非易失型内存(NVM)场景中进行内存加密所面临的数据一致性问题进行了讨论和解决。在使用NVM进行数据存储时,由于存储于NVM上的内存数据断点后不会消失,因此攻击者可以通过物理获得NVM的方式,强行读出被攻击这内存中的重要数据(如私钥等),从而完成攻击。为此,目前通常采用基于计数器的加解密(Counter Mode Encryption)技术,在保证额外开销很低的情况下,达到仅在NVM中存储加密后的数据的效果。
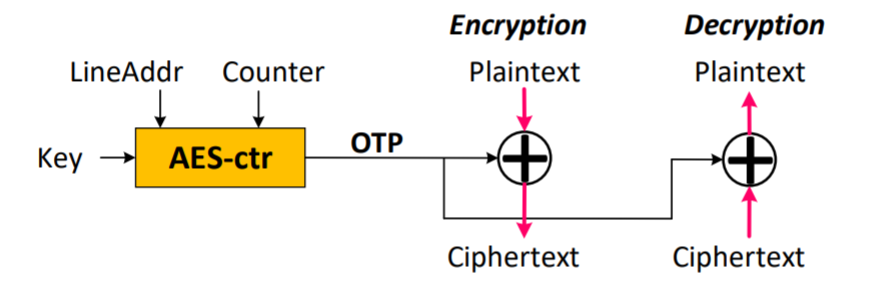
如上图,Counter Mode Encryption在内存管理器(Memory Controller)中对每一个内存地址添加了一个Counter,会在进行内存访问的同时,根据当前访问的地址和对应的Counter,生成一个One Time Pad(OTP),并使用简单的抑或操作来完成最终的加解密。通过将复杂的OTP生成和内存访问操作并行,Counter Mode Encryption可以有效降低加解密带来的额外开销。
在这一加密方法下,为了保证存储于NVM中的数据在断电后仍然能够被访问到,需要保证Counter和加密后的数据被同时原子性地持久化到NVM中。然而,目前出于性能考虑,对实际数据的写入会被缓存在易失的CPU Cache中,对Counter的写入会被缓存到易失的Memory Controller On-Chip Cache中,不存在保证两者同时原子性的被持久化的写回NVM中的方法。为了解决这一问题,目前已有一些不太完美的解决方案。一些方法使用大电池保证断电后Counter Cache能够完成写回操作,但由于Counter Cache过大导致对电池电量要求很高;一些工作采用添加新的原子性原语的方式保证两者原子性的被写入,但需要用户修改应用程序以使用提供的原语;另外一些工作使用扫描整个内存的方式进行纠错,恢复开销过大。
这篇工作则采用了删除On-Chip Counter Cache的方法,在每次对NVM进行写入操作时,于Memory Controller中进行控制,将对应的Counter和加密后的数据同时原子性的放入到NVM的Write Queue中。如下图,其中,Register用于暂时存放写入操作,以保证Counter和Data加入Write Queue的原子性。

然而,删除了On-Chip Counter Cache会导致每次对数据写回NVM的操作被放大为了将Counter和数据都写回NVM的两次NVM写操作,带来了高达1倍的额外性能开销。为解决这一问题,作者提出了两点优化:
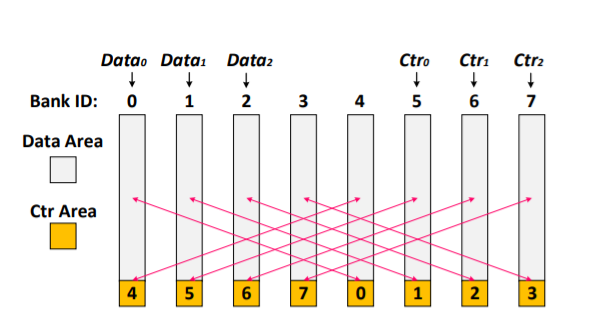
Cross-bank Counter Storage:充分利用内存写入时不同Memory Bank可并行写入的特性,合理安排数据和Counter的存储位置,使数据和对应的Counter、不同数据的Counter尽可能的分散在不同的Bank上,从而使用并行写入来隐藏两次写入所带来的额外延迟。如下图:
locality-aware counter write coalescing:NVM应用为了充分利用局部性,通常使用log的方式使得写入操作被集中在连续的内存地址中。同时,在Counter的实现上,连续的内存地址所对应的Counter也会被存储于连续的字节中。因此,在NVM应用中连续的log写入操作所对应的Counter写入通常也会在同一Cacheline上,可以被同时写入到NVM中。基于这一观察,如下图所示,作者采用了写吸收的方式,将连续的log写入所对应的counter更新一同持久化到NVM中,从而进一步减少了同一Bank上的额外写入操作

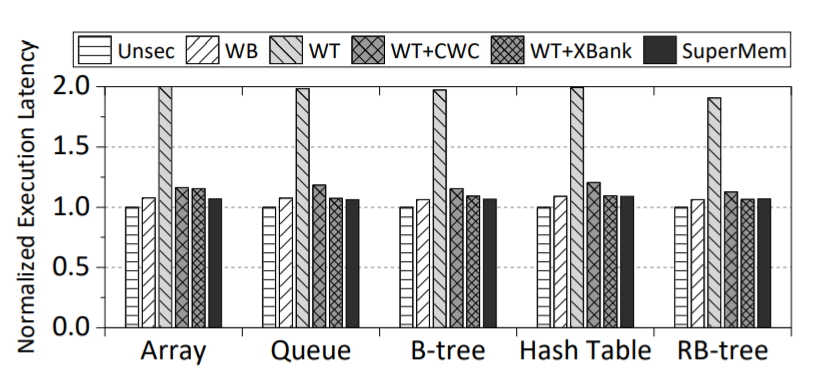
测试中,作者使用模拟器实现了这一硬件设计,并对不同优化的效果在一些数据结构上进行了测试。结果如下图所示,单纯的取消On-Chip Counter Cache(WT)确实会导致大约2倍的性能下降,之后再采用了不同的优化后(WT+CWS,WT+BANK)额外开销都会有显著下降,使用全部优化后的性能同原本的存在Counter Cache(WB)的性能相差无几,相比无加密(Unsec)的情况额外开销很小。
Yuanyuan Sun, Yu Hua, Zhangyu Chen, and Yuncheng Guo Huazhong University of Science and Technology
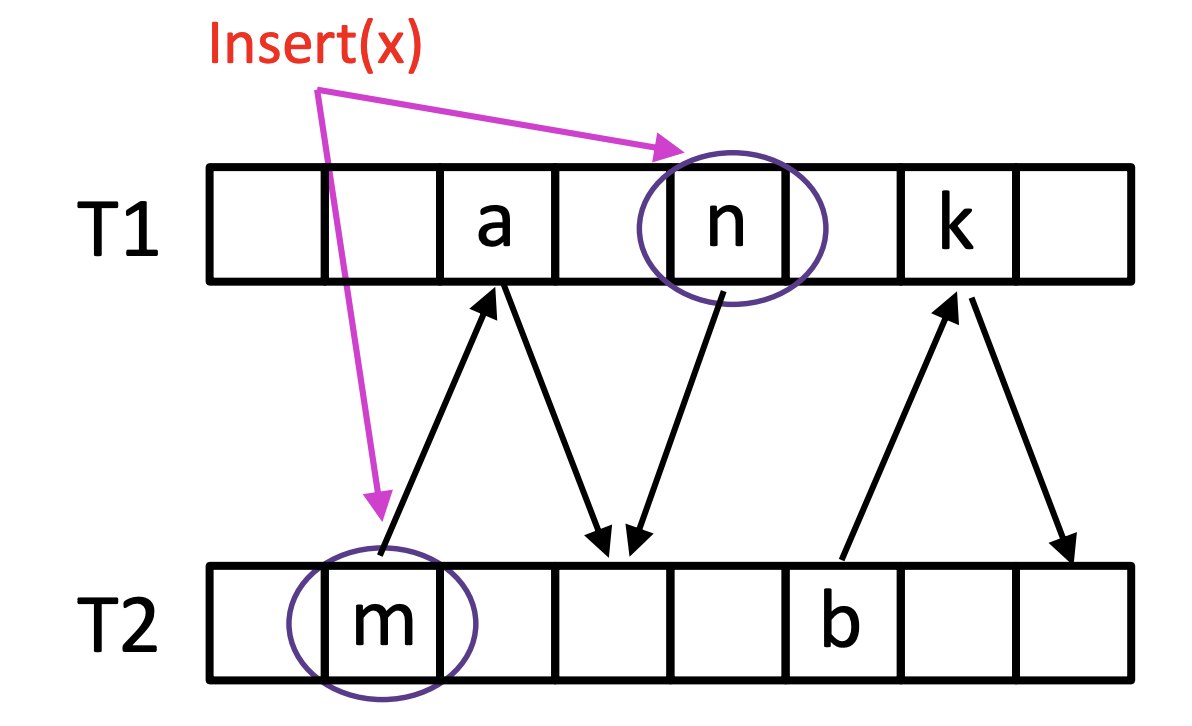
第一天session2的第6个报告是来自华中科技大学的工作,相关论文Mitigating Asymmetric Read and Write Costs in Cuckoo Hashing for Storage Systems发表在USENIX ATC'19上。Cuckoo hash是一种为了有效解决hash冲突,提高空间利用率并且能够在$O(1)$时间内能够进行迅速查找的哈希方式。在插入x的时候会计算两个哈希函数,找到两个表中的位置,放到任意一个空的位置。如果两个表中相应的位置都满,那么需要把其中一个位置中的值踢到另一张表中的相应位置,如下图所示。
然而,为了解决踢除的链成环的问题,导致cukoo hash在插入时候性能很差,造成读写性能不对称。另外,在并发情况下,发生踢除操作需要把两个表都锁上(libcuckoo@EuroSys’14)。
本文的目标是设计一种高吞吐、并发友好的cukoo hash,称为CoCuckoo。本文使用的方式是用图来表示这种踢除关系,通过图的性质来加速踢除操作,并且将锁的粒度控制在图上。CoCuckoo的图中一个节点表示hash table中的一个bucket,边是从一个item的storage点指向其backup点,如下图所示。因此,每一个非空bucket,都会出现在一个子图中。
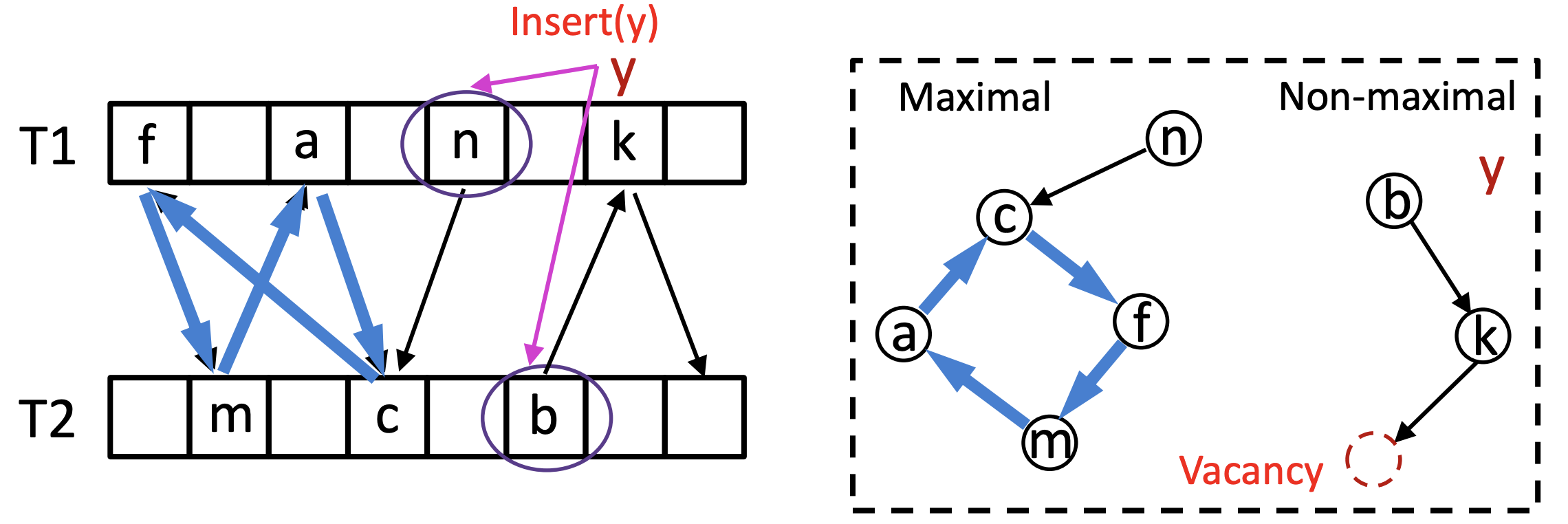
进一步,CoCuckoo将子图分为三类:空、(非空且)非满载、满载,并且将插入按照不同的子图情况分为六类,每一类对应一种子图模式。该工作分析了这六类情况下如何加锁。
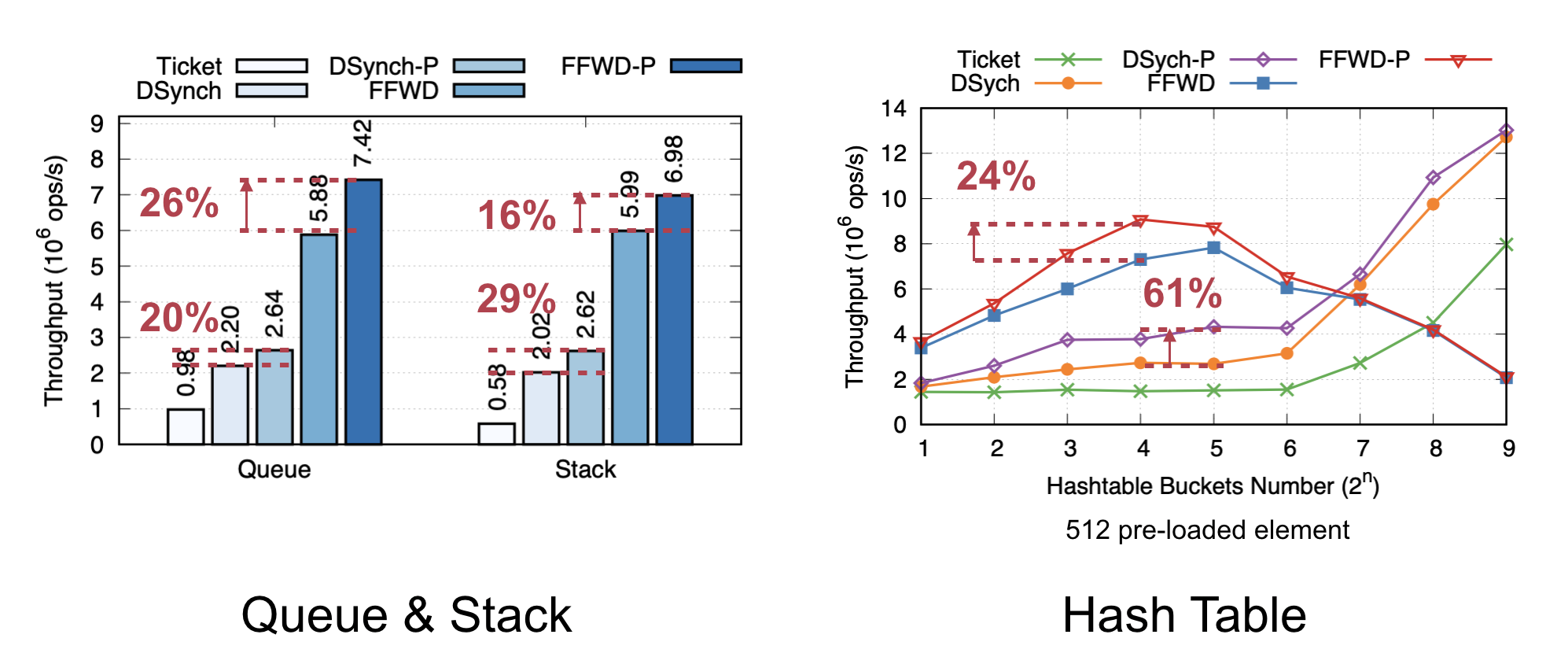
在测试用,该工作对比了libcuckoo@EuroSys’14,在YCSB下进行了测试,测试的参数为吞吐量、插入的预先决定模式以及额外的空间开销。测试表明,CoCuckoo对比2-way libcuckoo有75%-150%的写性能提升,证明了CoCuckoo设计的有效和高效。
这篇工作由华中科技大学和德州大学阿灵顿分校的研究者共同完成,发表于2019年的HPDC上,第一作者是来自华中科技大学的Hang Huang。
这一工作主要面向容器这一目前较为火热的技术。容器技术使用了操作系统内核所提供的Namespace和Cgroup的支持,做到了对文件系统、网络、性能等多个方面的隔离。在付出了不同容器共用同一内核的安全代价下,容器拥有远高于虚拟机等传统隔离方式的性能,目前在工业界已被广泛使用。
然而,由于不同的容器在共用同一内核的前提下使用了CGroup进行内存和CPU等的性能隔离,因此产生了语义鸿沟的问题。由于共用同一内核,因此不同容器共用相同的sys文件系统,应用程序在容器内通过系统调用所获得的系统资源状况(如CPU个数等)为整个系统的资源情况;而由于容器使用了CGroup来进行性能隔离,因此每个容器实际能够使用的资源为CGroup所规定的资源数目,而非系统的全部资源。这一鸿沟会导致应用程序的行为产生一些错乱。这里以在Java9针对容器添加支持前的Java虚拟机为例,Java虚拟机会根据系统的CPU数目创建对应数目的垃圾回收线程,由于未正确获得CGroup设置的CPU数目,Java虚拟机会创建过的垃圾回收线程,因此反而会由于线程过多而降低性能。
为此,该工作通过修改系统Namespace和CGroup的实现,并实现了一个虚拟的系统文件系统(Virtual SysFS)的方式,将CGroup对系统资源的限制通过SysFS传达给了Container中的应用,使得其中的应用能够通过传统的资源查询接口获得正确的资源数目。
除了简单的实现了正确的资源获取功能外,该工作还使用了一些启发式的策略,根据整个系统的状态,动态的调整暴露给容器的资源总量,从而为运行在容器中的应用提供一些提示,方便其中的应用基于提示做对应的优化。文中主要对CPU和内存做了探讨,具体的启发式策略较为复杂,这里只简要介绍思路:
CPU:在系统存在空闲CPU且容器所使用的CPU资源没有超过容器的CPU限额时,增加容器所能够看到的CPU数目。反之,降低容器所能够看到的CPU数目。
内存:在系统存在空闲内存时则逐渐增加容器所能看到的内存至hardlimit,即CGroup规定容器所能使用的最大内存;否则则降低至softlimit,即CGroup规定的容器所能使用的最大物理内存,超出后则会开始swap。
在给与应用提示后,应用便可根据看到的资源数目做相对应的调整,从而尽可能的提高效率,利用系统资源。为此,需要对应用程序进行修改。针对之前所提到的CPU和内存而言,应用程序可以:
根据CPU信息调整并行度。对于Java虚拟机而言,垃圾回收开始前根据有效CPU数目决定唤醒的垃圾回收线程数;对于OpenMP这一并发编程API而言,每次并行工作开始时根据CPU数目决定唤醒的线程数目。
根据动态内存信息进行内存管理。对于Java虚拟机而言,有效内存变大后通过修改young max和old max信息,自适应地调节堆大小;有效内存缩小后则先触发垃圾回收,之后再缩小young max和old max,后续再进行堆大小的调整。
测试结果现实,利用这些启发式的策略后,应用程序性能能够得到很大提高。使用了CPU策略后,在对Java虚拟机的测试中,相对于原始的OpenJDK8而言,本文可获得最最多49%的性能提升,减少80%的GC时间。对比于添加了容器支持而OpenJDK而言,本文工作也可减少42%的GC时间。此外,对OpenMP这一框架而言,本文工作也可达到最高4倍的性能。使用了Memory策略后,内存过度使用现象大量降低。
第二天的keynote是由来自新加坡国立大学的何丙胜老师带来的关于联邦学习系统的基本介绍和面临的机遇与挑战。
现如今,隐私保护正受到越来越多人的重视,各个国家和地区关于隐私的法律法规也日趋完善,然而用户也需要由隐私信息获得定制化的服务。为了解决隐私保护和使用隐私数据之间的矛盾,人们提出了联邦学习的概念。联邦学习是一种分布式的机器学习框架,主要用于在保证数据隐私的前提下,结合多个参与者方数据共同完成模型训练。联邦学习技术不需要所有训练数据被集中到一个数据中心再进行训练,而是采用如从统一服务器下载模型、利用本地数据训练并返回参数更新等方式,使得隐私数据在不被泄漏的前提下参与模型训练。
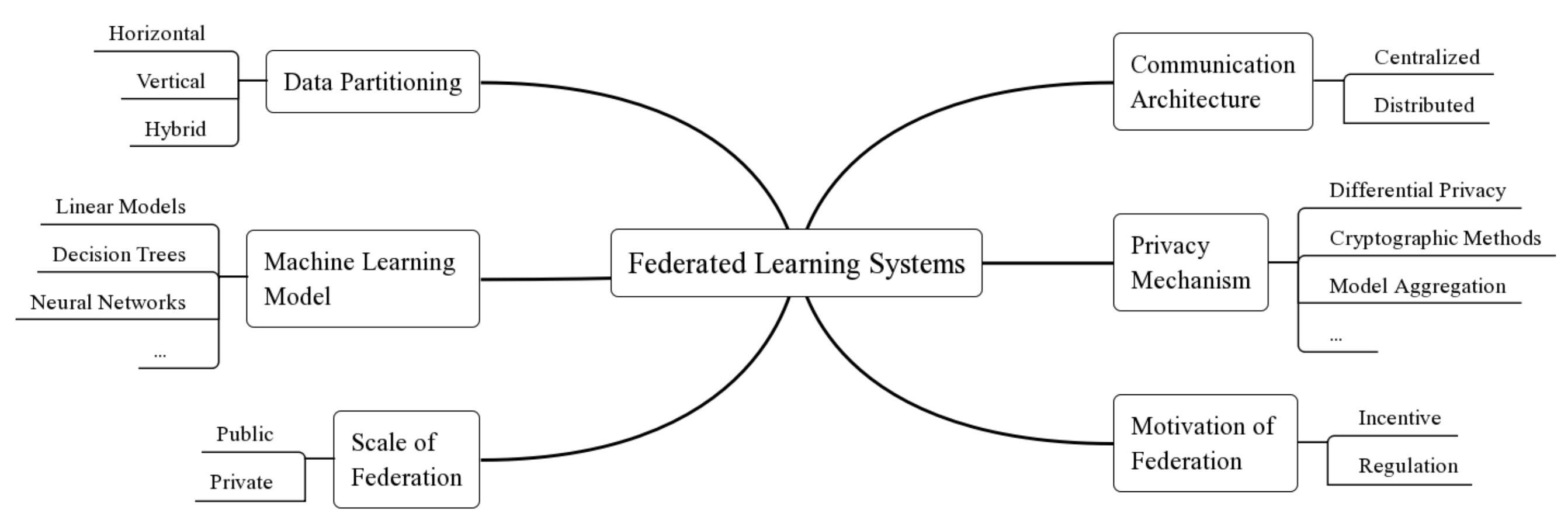
何老师进一步阐述了现有联邦学习系统的六个分类维度:data distribution、machine learning model、privacy mechanism、communication architecture、scale of federation 以及 motivation of federation,并就data distribution维度进行更详细的阐述。简单来说根据sample space和feature space的分布方式,data distribution存在垂直和水平两个方向,水平方向指需要集合各个参与方相同类型的数据(sample space交集少而feature space重合多),而垂直方向则需要同一实体在多种类型数据中的资源(feature space交集少而sample space重合多)。
在这些维度的基础上,何老师阐述了现有系统的不足之处及相应的挑战。对于data distribution角度来说,现有系统大多关注于水平划分方向,并且少有框架针对hybrid的模式进行优化。对于privacy mechanism来说,现有的加密方法(如同态加密)会带来较大的额外开销,其次不同场景需要应用不同的隐私策略,因此需要提出更灵活、更高效的隐私保护机制。另外在异构场景下,例如部分设备是低功耗IoT设备的情况下,如何完成比较重量的训练过程也富有挑战性。
Keynote最后是大家对于联邦学习的一些讨论:
包老师问:有人说政府面前没有隐私,怎么看待个人隐私和政府的关系?
何老师答:如何在隐私和政府及公共安全方面进行妥协是亟待解决的,联邦学习对隐私进行保护的同时能够完成策略学习的特性有可能成为解决矛盾点的契机。
宋老师问:由隐私数据导出的其他数据(模型、决策)是否仍然需要保护?
何老师答:这是一个open question,privacy的定义是非常多样的,我们所知有数十种,其次不同隐私政策也会影响由隐私数据导出的结果的隐私性。
陈老师问:联邦学习的关键点在什么?它看上去更像是多个其他问题集合成的一个新概念。
何老师答:的确,现在我没有找到这样一个关键点,它是非常多个细分问题的集合,就像是云计算这个概念一样,但这确实是一个新的场景,会引发更多的机遇和挑战。
本keynote主要基于survey的工作https://arxiv.org/abs/1907.09693。
Jie Lu, Liu Chen, Lian Li, and Xiaobing Feng Institute of Computing Technology, Chinese Academy of Sciences
此篇来自SOSP 2019的paper在我们之前公众号的SOSP 2019的推送中已经详细阐述。
Zhihui Zhang, Jingwen Leng, Lingxiao Ma, Youshan Miao, Chao Li, and Minyi Guo Shanghai Jiao Tong University, Peking University and Microsoft
这篇工作基于SAGA^2^的GNN计算抽象,对现有GNN算法进行了分析,并提出了一个GNN Benchmark方法,同时从算法,软件,体系结构不同方面给出了具体测试分析结果。
目前的深度学习方法,对数据之间的关系表示大多都基于Grid,例如文字的序列关系,以及图片不同分块的二维平面关系。但在现实生活中,数据之间实际上是更为复杂的图关系,例如社交网络,分子结构等。GNN就是用来处理这类数据的神经网络方法。
GNN可以表示为一个Graph,其目标是获得每个结点上的表示$hv$。每个节点的$hv$由这一节点的特征、这一节点的邻边以及邻居的特征计算而得。GNN的训练过程可以抽象为SAGA,及Scatter,ApplyEdge,Gather,ApplyVertex,训练的每次迭代过程都含有这四个步骤。Scatter阶段会将每个节点上的$hv$发送给其邻边,ApplyEdge阶段每个边基于具体算法对Scatter阶段发送的数据进行处理,Gather阶段每个节点会收集其邻边上的信息并进行根据具体算法进行聚合,最后ApplyVertex阶段将聚合后的信息与自己上一次迭代的结果,根据具体算法计算出新的$hv$值。
这篇工作为了分析不同GNN方法的性能,基于SAGA抽象进一步提出SAGA^2^,将Gather拆分为Gather,Aggregate阶段,其中Gather仅进行邻边信息的收集,而Aggregate阶段则将收集到的信息根据具体算法进行聚合。基于这一抽象,这篇工作对目前的50多种不同GNN算法中不同阶段的操作进行了调研总结,得出了这些不同算法在不同阶段实际上选取的算子种类较少的结论。
从这些GNN算法中,作者继续选取了6个能覆盖不同阶段中大部分可能用到的操作算子的,具有代表性的算法在不同的数据集下进行了Benchmark,同时对不同stage的执行情况进行了breakdown,并得出以下结论:
Ji Zhang, Yu Liu, Ke Zhou, Guoliang Li, Zhili Xiao, Bin Cheng, Jiashu Xing, Yangtao Wang, Tianheng Cheng, Li Liu, Minwei Ran, and Zekang Li Wuhan National Laboratory for Optoelectronics, Huazhong University of Science and Technology, Tsinghua University, Tencent Inc.
对于数据库系统的配置调参会对数据库的性能有很大的影响,但即便是有经验的数据库管理员也很难将配置调整到最优。特别是在云数据库的大环境下,海量云应用有着不同的工作场景,都需要针对性的数据库参数,人工调参已无法适应云数据库大背景,需要由自动化的方法来完成。
现有的自动化数据库配置调参工作有以下问题。现有基于配置搜索的工作需要对巨大搜索空间内的配置进行搜索,1)时间开销很大;有可能2)陷入局部最优的配置,3)云数据库环境的变动会导致重新搜索。现有基于学习的工作1)基于流水线式的学习模型,上一阶段的最优结果无法保证可以得出当前阶段的最优结果;2)需要基于高质量的学习样本才可以学习出较好的配置;3)无法适应大量的可调节“旋钮(Knob)”并找出最佳配置,4)云数据库环境的变动会导致模型重新训练。
针对以上问题,这篇文章提出了CBDTune(Cloud DataBase Tuning system),以端对端的方式使用深度强化学习进行自动化配置。
通过使用强化学习,该工作使用回报函数(Reward Function)返回的回报(当前配置调试对云数据库产生的影响)来对配置进行端对端的调试。下图显示了CDBTune如何将数据库场景应用到强化学习中。CDBTune根据当前状态和当前的策略(即深度神经网络模型),推理出对数据库配置的调整。在对应的调整被应用后,根据云数据库的状态变化得出性能变化,作为回报传入CBDTune作出对应策略的完善,然后进一步执行强化学习的迭代,进而得出最终策略。同时,CDBTune的强化学习也是一种端对端的配置调参方式,通过由数据库性能生成的回报,避免了现有基于机器学习调参多个阶段的最优无法得出全局最优的问题。而且,不像监督学习和非监督学习,基于强化学习的CDBTune无需对训练样本进行标注,根据最终的性能作为回报函数,适用于所有场景和硬件配置,有很强的的通用性。
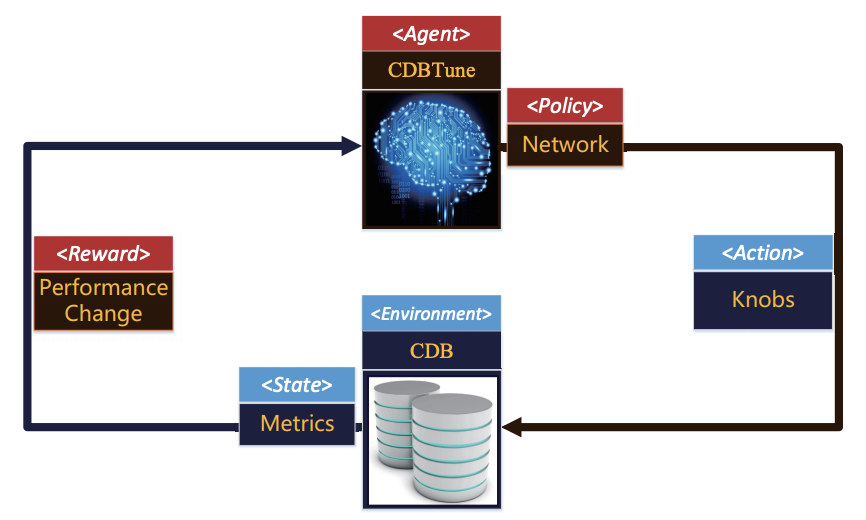
在强化学习中,由于需要调试的旋钮数量很多,操作空间(action space)过大,且无法处理连续的调参操作,造成现有许多强化学习策略不能适用。CDBTune采用了深度确定性策略梯度方法(DDPG)来解决上述问题。DDPG的好处是无需为每个操作存储对应的效果值(采用该操作获得的预测提升效果),而直接通过当前状态计算出所需连续操作的效果值。
另外,CBDTune仅需要少量的学习样本,其原因是CBDTune通过不断试错来获取最终策略,每次试错生成少量样本,在数据库配置调参场景下已经足够用来训练强化学习策略。这样的方式虽然不保证获得全局最优,但是相比于现有方法会尝试更多的配置可能性,避免陷入局部最优的可能性。
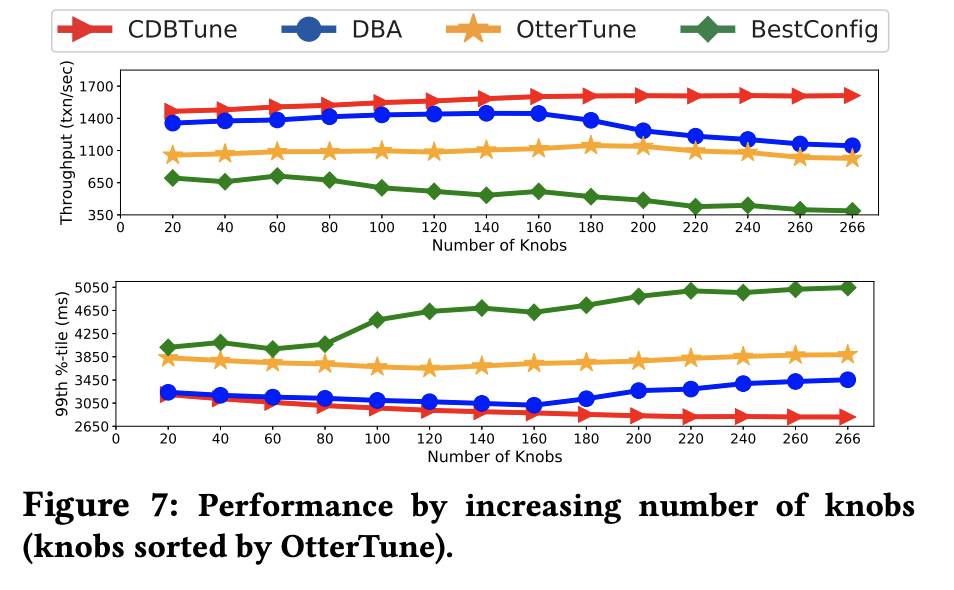
最终的测试显示,相比于现有工作OtterTune,BestConfig和数据库管理员人工调整配置,CDBTune得出最终配置所需的执行时间最短。在TPC-C数据库测试标准下,CBDTune最终输出的云数据库配置对应的数据库有着最高的性能,且随着旋钮数量增加,CDBTune相比其他工作的性能提升变大。
Ke Yang, Mingxing Zhang, Kang Chen, Xiaosong Ma, Yang Bai, and Yong Jiang Tsinghua University, Qatar Computing Research Institute, HBKU, 4Paradigm Co. Ltd.
此篇来自SOSP 2019的paper在我们之前公众号的SOSP 2019的推送中已经详细阐述。
Li Zhihao, Haipeng Jia, and Chen Tun Institute of Computing Technology, Chinese Academy of Sciences
AutoFFT: A Template-Based FFT Codes Auto-Generation Framework for ARM and X86 CPUs (SC 2019)
Li Zhihao1, Haipeng Jia1, and Chen Tun1
这篇论文来自中科院计算所,文章提出的是一个基于模板的高性能快速傅里叶变换(FFT)代码生成框架,生成的程序可以高效地运行在ARM和x86平台上。
离散傅里叶变换(DFT)广泛应用于科学计算和图像、信号处理,它将一个长为n的输入序列X,通过与旋转因子W的乘积和求和操作,从时域转换到频域,下图是它的公式。
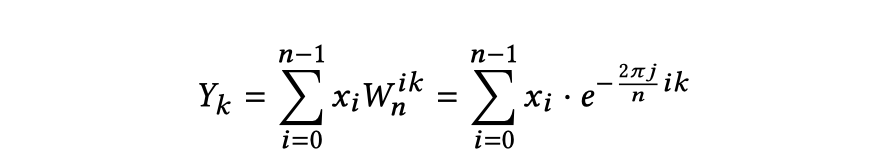
该公式也可以写作以下n × n的旋转因子矩阵与输入序列的乘积。朴素的矩阵向量乘的复杂度为$O(n^2)$,因此依据定义计算DFT有平方复杂度。而FFT算法能将计算长度为n的序列的DFT的复杂度从$O(n^2)$降低到$O(nlogn)$。
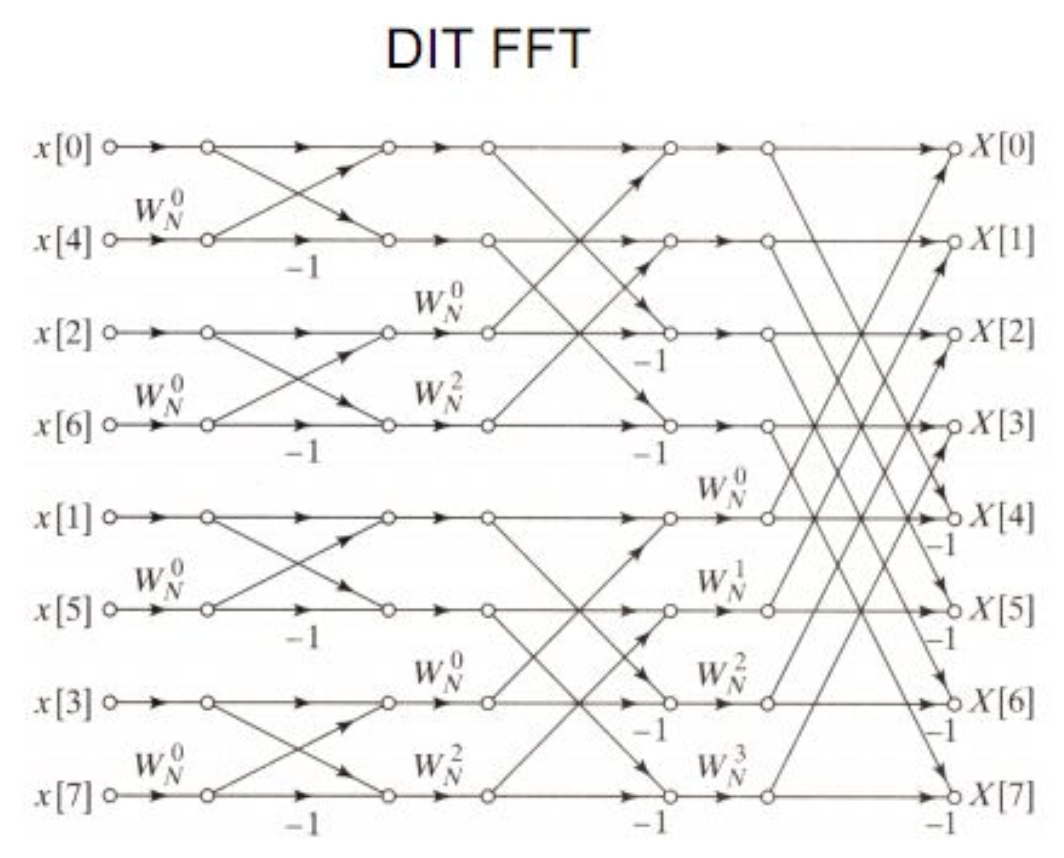
Cooley-Tukey算法是目前应用最广泛的一种基于分治法的FFT算法,将大的DFT计算序列分解为多个小的DFT序列。分解的基底长度可以是2的幂或质数。计算的过程可以使用蝶形网络(butterfly diagram)来描述,网络的基本计算单元称为蝶形。
对于特定长度的输入,选取不同的基底,会有不同的蝶形网络。下图是一个对长为8的序列使用单一的2基底构建的蝶形网络,网络左侧为输入,沿横轴向右流动,从一条横轴指向另一条横轴的有向线段代表一个数据与另一个数据进行加/减操作,最终得到右侧的输出。
可见,Cooley-Tukey算法只对基底进行DFT运算,因此可以将算法分为两个步骤:
Install-time:实现对基底进行DFT运算的蝶形
Runtime:依据输入的大小,选取基底,构建网络
算法的优化也是从这两个方面考虑,
如何对特定长度的基底构建尽可能快的蝶形
如何选取最佳的网络
论文着重于install-time的优化。由于理论上存在无穷多的质数和2的幂,因此有无穷多的基,也就要实现无穷多种类的蝶形。每个蝶形的实现和算法复杂度都有一定区别,往往是基越大实现越复杂。传统的实现高效蝶形的方法是针对不同的架构平台手动编写汇编代码,有较高的开发难度,且依赖于具体的平台架构。现有的可移植的自适应调优框架则生成的是高级语言,性能不能满足高性能计算的需要。本文提出的基于模板的自动代码生成框架,则实现了自动生成适用于ARM和x86平台的高性能汇编代码。
该框架主要挖掘了旋转因子W在复平面上的数学性质。
对于长度r为质数的基,依据W在复平面上关于x轴的对称性,经过公式推导得到了输出$Yk$与$Y{r-k}$之间的相似性(论文将该结论称为质数基的pair pattern),从而使得经过计算可以同时得到$Yk$与$Y{r-k}$。
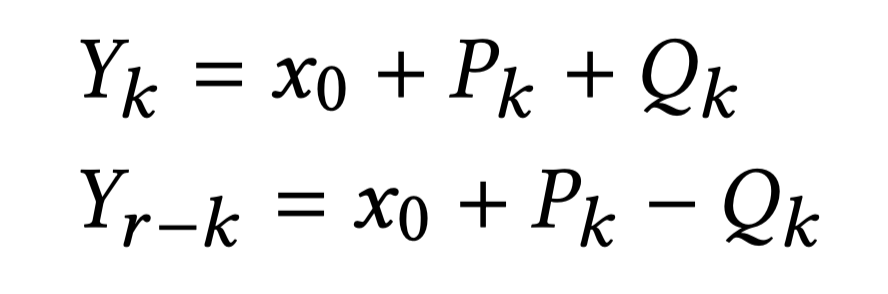
r为2的幂时,$Wr^{ik}$, $Wr^{{r-i}k}$ , $Wr^{{r/2-i}k}$,$Wr^{{r/2+i}k}$之间有着更好的对称性,且对于$Yk$当gcd(r,k)不等于1时,$Yk$的旋转因子还存在着周期性。通过推导,可以同时算出$Yk$,$Y{r-k}$、$Y{r/2-k}$与$Y{r/2+k}$,该结论称为quad pattern。

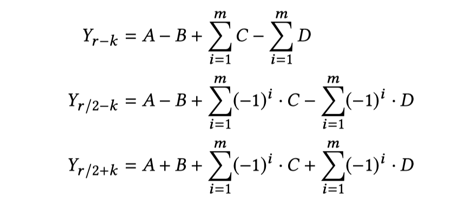
报告中指出,使用上述优化方法,蝶形的算法复杂度在常数上能够降低一个数量级。依据公式推导本文实现了生成蝶形的代码模板。本文分别定义了三个版本的模板函数与汇编指令的对应关系:使用ARM/x86平台SIMD指令的两种,和未使用SIMD指令的一种。由于向量寄存器数量的限制,SIMD指令优化目前仅用于r < 13的基。
关于Runtime优化,论文简略介绍了其方法:对输入长度n进行因数分解,生成一课因数分解树,树的每个分支代表一次factorization。依据不同的分解方式及其他参数会生成不同的蝶形网络。Cooley-Tukey算法是内存敏感,因此性能评估器采用DFS搜索树根到叶子的最短路径,对因式分解式进行剪枝,使得蝶形网络计算层数更少,从而占用更少内存。接下来评估器通过不同的输入来评估候选的网络的性能,并通过自顶向上的动态规划方法减少重复的计算。
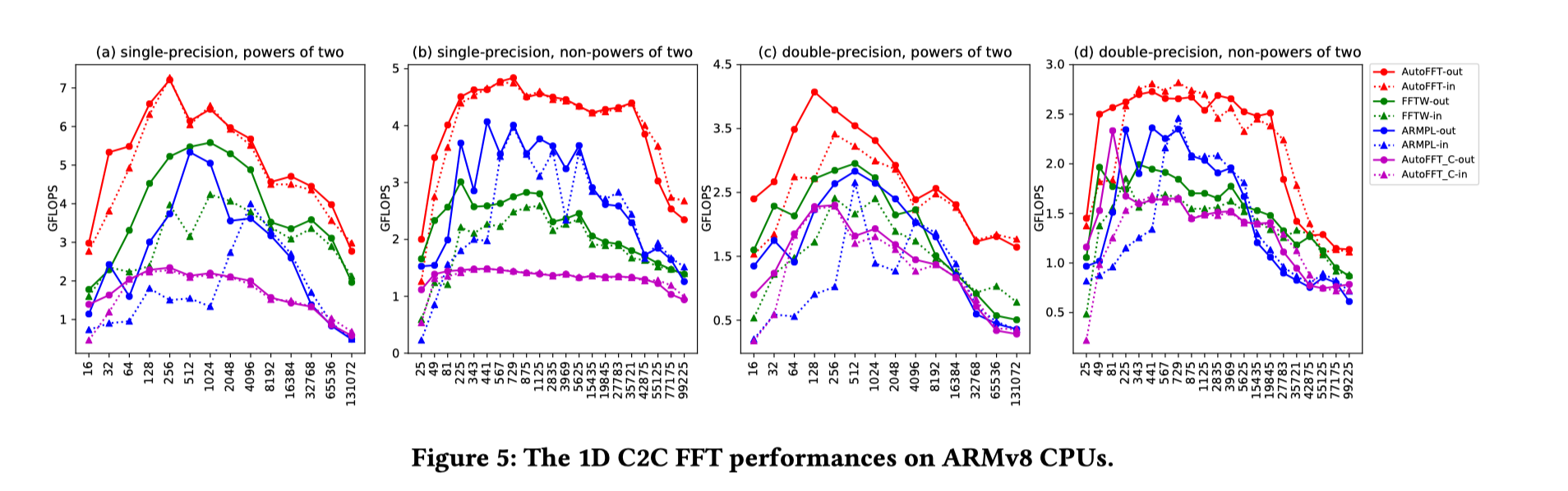
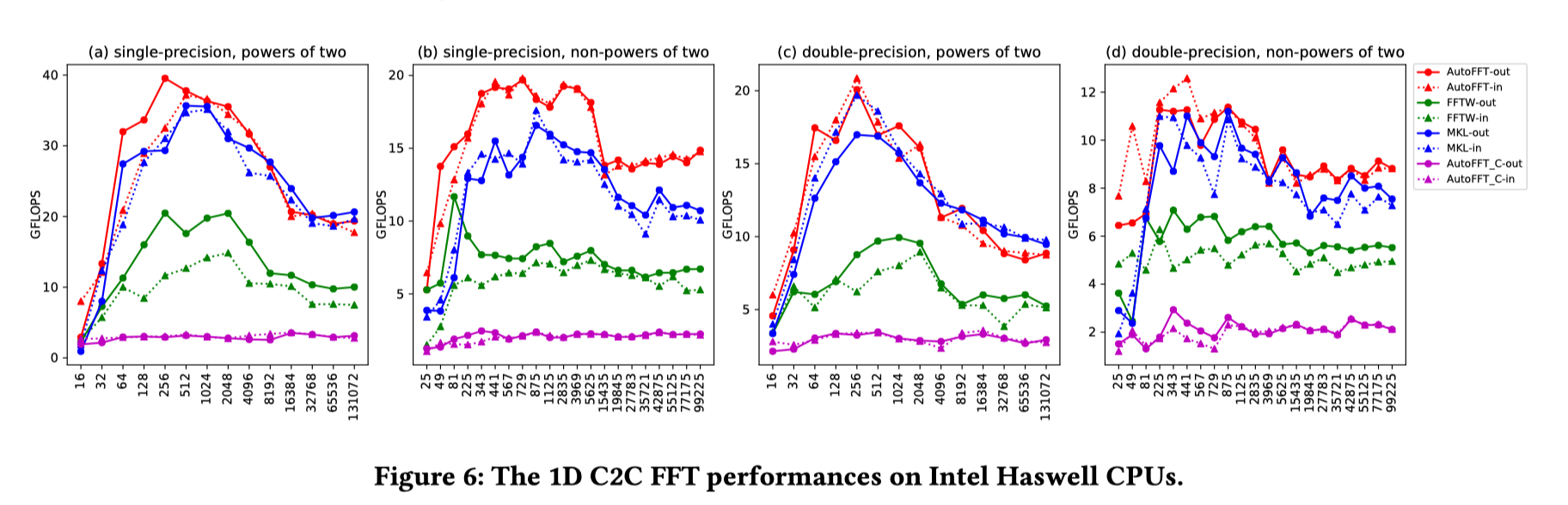
评估部分,在ARM和x86平台上,AutoFFT(红线)对此了FFTW(绿线)、vendor-tuned library(ARMPL/MKL,蓝线),以及C版本的AutoFFT(紫线)。评估结果如下横,轴是数据规模,纵轴是性能(GFLOPS)。这些库支持不同的计算配置(complex/real、out-of-place/in-place等),本文进行了分别的测试。可见在ARM平台上,AutoFFT相对于C版本均有很大提升,且均超过了FFTW和ARMPL的性能。除在x86平台的real FFT性能出现过低于Intel MKL的性能,其余情况基本优于各种现有FFT实现。
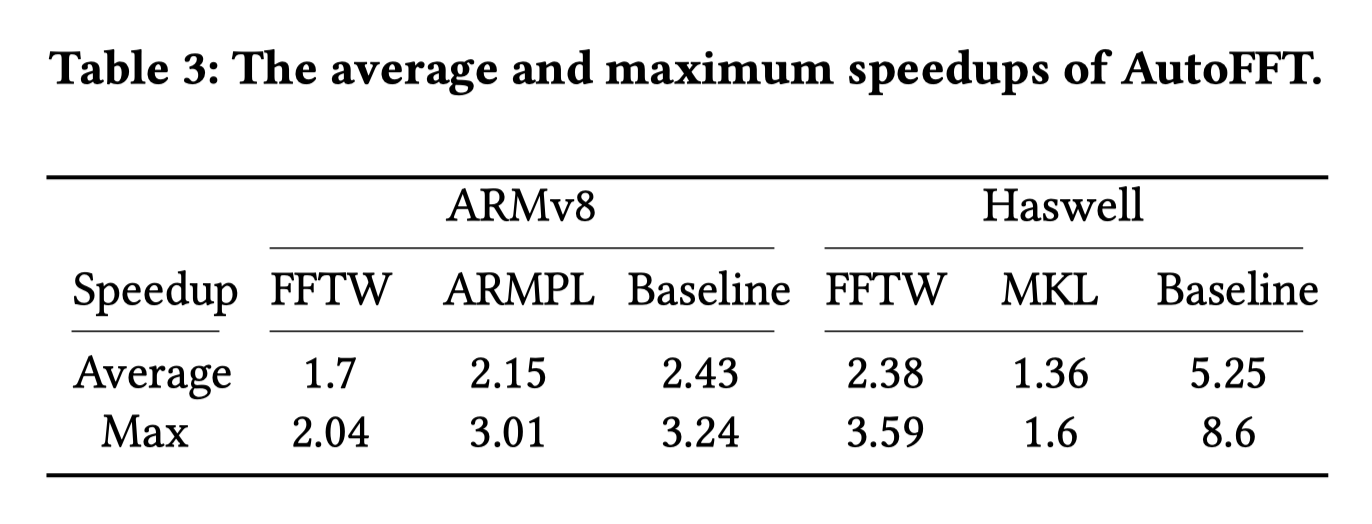
平均加速比如下所示:
Xuan Peng, Xuanhua Shi, Hulin Dai, Weiliang Ma, and Qian Xiong Huazhong University of Science and Technology
本文作者来自华中科技大学。作者指出,目前深度学习模型参数数量迅速增大,相对而言GPU内存大小是一个非常缓慢的发展,因此需要采用一定的内存管理方法来确保GPU内存能够容纳模型训练过程中占用的内存,同时保证训练的高效性。
作者分析了Deep Learning训练过程的内存占用,认为主要可以分为四个部分:1. 参数 2. 前向传播的输出 3. 反向传播的输出4. CNN卷积层的额外空间。其中参数需要一直存放在内存中,反向传播在当前阶段计算完后即可释放,而前向传播的输出在前向和后向过程汇总均需要用到,因此是实际内存占用的绝大部分。
现有的GPU内存管理方法也是针对前向传播,主要分为两类:
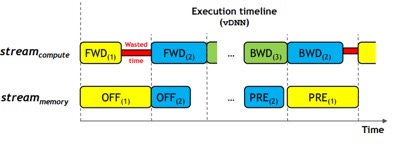
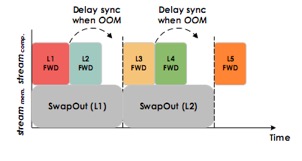
作者发现,1. 由于硬件的异构性,在特定硬件上swap时间可能数倍于计算时间; 2. 同类型的卷积层执行时间可能有很大的差距。作者将这些问题总结为:1. 现有仅基于静态图分析的方法,不能很好地应对硬件的异构性,无法应用于imperative计算;2. Heuristic并不总是有效且无法应对新的类型的网络;3. 且无法定量分析,比较方法孰优孰劣。
本文的方法基于两点观察:
无论是symoblic还是imperative的执行都是基于tensor的。
训练过程iteration之间的tensor访问存在规律,通过分析这个规律可以直到内存管理方式。
因此,本文提出的系统中包含一个tensor track,为tensor添加额外的identity信息并收集运行时tensor访问次数。收集到的信息将提供给系统的另一部分——policy maker。
由于系统可能在刚刚启动时遇到OOM,因此即使尚无收集到的数据也支持按需的换入换出。收集到数据后系统支持以下策略:
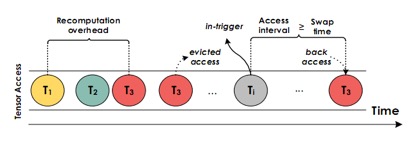
反馈调节。在运行时检测基于策略1设定的in trigger时间能否让tensor及时换入,若不能则提前这个时间。
尽可能多的保留最新的重计算产生的tensor,在降低内存消耗和提高性能之间达到平衡。
基于以上方法,相对于现有方法能够允许的batch size有1.29倍到2.42倍的提升,训练时间加快1.03到3.86倍。该方法也是计算图不可知的,支持定量地评估,对于不同的网络更为通用,较好地解决了作者提出的问题。
本文由以下作者共同完成: